Last year at the Ignite conference - remember physical conferences? - Microsoft announced Project Cortex, a group of technologies that would sit behind SharePoint Online, providing AI enhanced metadata, search, and content curation services.
While there has been an invite-only private preview running for a while, it wasn’t until this years’ virtual Ignite, that most of us got to get our hands on anything Project Cortex related, and in this case, it was SharePoint Syntex.
Just what is SharePoint Syntex? (And yes, it really is spelt that way)
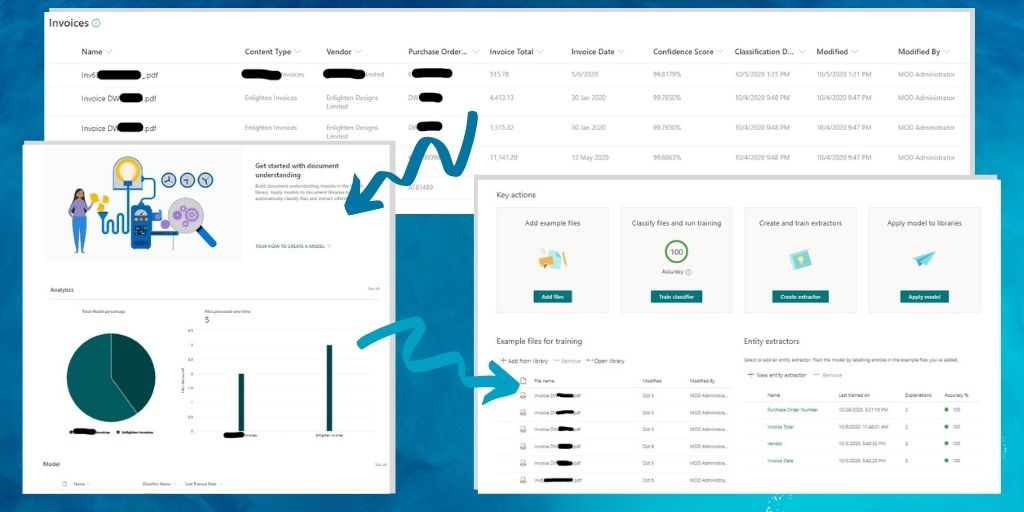
Syntex uses AI to extract data from a document and stores it in metadata fields attached to that same document, in SharePoint Online.
Some of you will be familiar with AI Builder in Power Apps, in particular the Forms Processing Module, or the Azure Forms Recognizer service – essentially the same service, but wrapped up in the SharePoint UI, with a lead-you-by-the-nose wizard to get you underway.
Note: when I tried to check out Syntex, it wasn’t available in any of the existing tenants that I had admin access to and it’s not included in the M365 E5 licence either. However, I was able to create a new trial tenant and activate a 30-day trial. Licenses are normally US$5/user/month – which could be a barrier to some.
A colleague of mine recently built a proof of concept in Power Apps AI Builder Forms Processing for a client. It didn’t take long - essentially less than a day - to build a basic Power Automate flow to grab PDF invoices from emails received from a few different vendors, train the model and spit out an XML file of the data pulled from the invoices. Having this background knowledge set a bit of a precedent and gave me something to compare SharePoint Syntex with.
Top tip: Read the instructions first!
Initially I just dived right in and tried to complete the wizard without reading any of the documentation, but some of the concepts were confusing, unintuitive and repetitive, so make sure you take a moment to read through the documentation that’s available and watch the demos. It'll make a huge difference to your understanding.
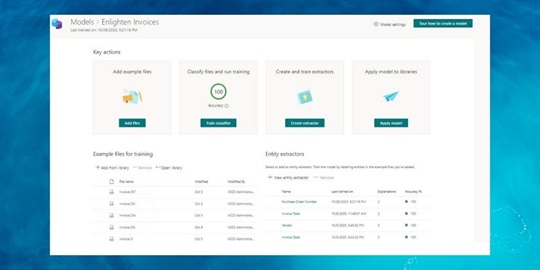
In short, the steps are:
- Create a new SharePoint Syntex Content Center site collection.
- Create a new model – content type.
- Show/train it how to identify which documents the model will understand – classifiers.
- Show/train it how to extract data out of the documents – entity extractors.
- Map the data to fields in the content type.
- Assign the model to a document library.
- Drop documents into the document library, wait a bit and then discover that the metadata has been populated for you!
Sounds easy - And it kinda is. Once I got my head around the separation between training it to identify the right kind of document versus training it to find the data fields I wanted to extract, it wasn’t too bad.
The whole document identification was a key thing that seemed to be missing from the Forms Processing Module in AI Builder, as my colleague had to find her own way to identify which documents were appropriate for a model - file name pattern in this case.
I also found that documents containing additional information, near to the information I was extracting, would then cause the model to extract the wrong data, and reduce its confidence score. The lesson here? If there are variations in layout - for example, if a client PO number is included on an invoice - you will likely need to include a separate model.
I also couldn’t see how to pick up repeating rows, such as invoice line items, which AI Builder handles, but also doesn’t make a whole lot of sense in a SharePoint document library. Standard practice, if you must keep it all in SharePoint, is to push any complex multi-value fields out to a related list.
So, what do I see SharePoint Syntex being used for?
Well, in its current form, it’s unlikely to be invoices (who knew? I happened to choose a bad test case, unless you only ever have one line-item per invoice.)
I can see it being used to capture data from a variety of form types, just not ones that would lead to parent-child relationships in the data. This could still be forms like course-completion surveys, meal menu selections, work requests, H&S forms, and many others. It could be well placed to tackle legacy paper filing, because all your current forms are already digital, right?
Still, it’s early days and I’m sure we’re going to see more from Microsoft in this area, to say nothing of the rest of Project Cortex.
Digitally transform your IT ecosystem
The Modern Workplace team at Enlighten Designs are all about developing comprehensive strategies to digitally transform the IT ecosystem of clients into a modern workplace. We work with you to build a digital infrastructure that fosters collaboration, productivity and engagement through connecting your employees and your clients seamlessly - anywhere and on any device.
Ready to empower your organisation? Our Empower with Teams package is based on best practice and industry standards - contact us to find out more.